



〒100-6114
東京都千代田区永田町2丁目11番1号
山王パークタワー12階(お客さま受付)・14階
東京メトロ 銀座線:溜池山王駅 7番出口(地下直結)
東京メトロ 南北線:溜池山王駅 7番出口(地下直結)
東京メトロ 千代田線:国会議事堂前駅 5番出口 徒歩3分
東京メトロ 丸の内線:国会議事堂前駅 5番出口
徒歩10分(千代田線ホーム経由)
セミナー
事務所概要・アクセス
事務所概要・アクセス
事務所概要・アクセス
〒100-6114
東京都千代田区永田町2丁目11番1号
山王パークタワー12階(お客さま受付)・14階
© Ushijima & Partners All rights reserved.

米国OpenAI社が提供する「ChatGPT」は、質問に対してまるで人間のように回答することなどから話題になり、日本企業においても利用を考えるところが増えています。
しかしながら、報道を見ていると、個人情報の漏えいのリスクがある、著作権を侵害する可能性がある、秘密を第三者に提供することになるなどの懸念が示されているようです。
本稿では、企業がChatGPTをはじめとするAI技術のサービスを利用することの可否、及びその際のルールを策定する際に法的に検討すべき事項を検討します。(2023年6月21日更新)
ChatGPT(https://chat.openai.com/)とは、米国OpenAI社が提供するサービスの1つであり、大規模言語モデル(LLM:Large Language Model)をチャットとして実装したものです。
昨今しばしば話題になる「ChatGPTを利用してよいのか?」という論点は、次の3つの場面に分けて考える必要があると考えられます。
(1) ChatGPTに質問(プロンプト)を入力し、回答を得る
(2) APIを利用して、再学習(ファインチューニング)や文章のベクトル化(埋め込み)等を行う
(3) 得られた回答を業務で利用する

現状の報道や議論においては、これらの場面が混同されていることも多いように見受けられます。
以下では、それぞれの場面について順次検討していきます。
検討においては、法務・コンプライアンス部門の皆様にとってなじみがあると思われる経済産業省「AI・データの利用に関する契約ガイドライン -AI編-」(平成30年6月。以下「AI契約ガイドライン」といいます)の概念と対比しながら、解説します。
https://www.meti.go.jp/policy/mono_info_service/connected_industries/sharing_and_utilization.html
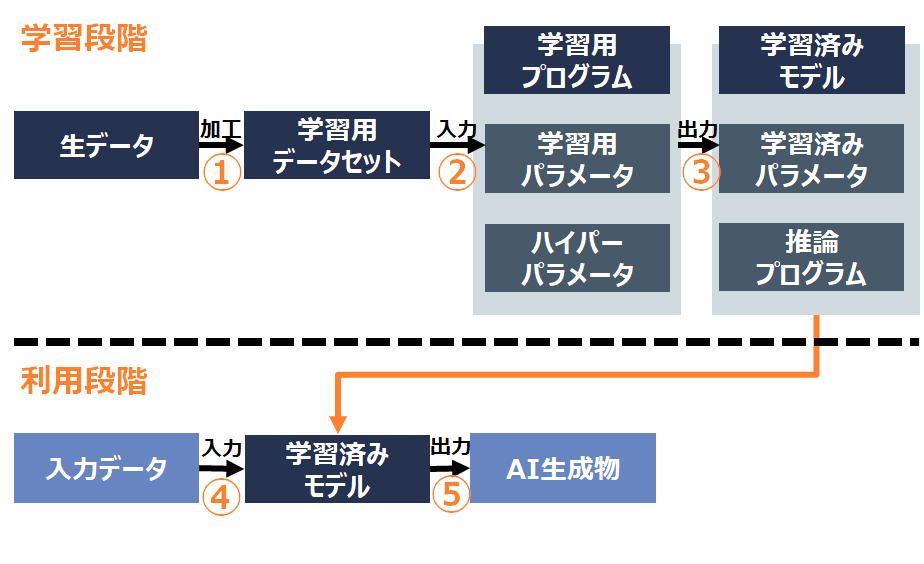
ChatGPTに質問(「プロンプト」と呼ばれます。)を入力し、回答を得ることは、AI契約ガイドラインでいう「利用段階」ということになります(下図の④及び⑤)。
ChatGPTにプロンプト(質問)を与えると、OpenAI社にデータが送信され、処理された後、回答が表示されます。
したがって、プロンプトに個人情報が含まれる場合、この一連の処理は個人情報の利用に当たりますので、個人情報保護法の規制を受けることになります。
ChatGPTに質問をして回答を得ることが、特定された利用目的の範囲内であり(17条・18条)、本人に対して通知等されている必要があります(21条)
個人情報保護委員会が2023年6月2日に「生成AIサービスの利用に関する注意喚起等について」を公表しました。このうち「生成AIサービスの利用に関する注意喚起等」において、以下のとおり利用目的に注意するよう記載されており、利用目的が個人情報保護法遵守の観点から重要なポイントであることが分かります。
(1)個人情報取扱事業者における注意点
①個人情報取扱事業者が生成 AI サービスに個人情報を含むプロンプトを入力する場合には、特定された当該個人情報の利用目的を達成するために必要な範囲内であることを十分に確認すること。
② 個人情報取扱事業者が、あらかじめ本人の同意を得ることなく生成 AI サービスに個人データを含むプロンプトを入力し、当該個人データが当該プロンプトに対する応答結果の出力以外の目的で取り扱われる場合、当該個人情報取扱事業者は個人情報保護法の規定に違反することとなる可能性がある。そのため、このようなプロンプトの入力を行う場合には、当該生成 AI サービスを提供する事業者が、当該個人データを機械学習に利用しないこと等を十分に確認すること。
詳細はニューズレター「生成AIサービスに関する個人情報保護委員会からの注意喚起と実務への影響」をご参照ください。(2023年6月21日の追記は以上)
個人情報保護法では、「提供」とは、個人データ、保有個人データ、個人関連情報、仮名加工情報又は匿名加工情報(個人データ等)を、自己以外の者が利用可能な状態に置くことをいうとされています(通則ガイドライン2-17)。
したがって、例えばクラウドサービスにおいては、「クラウドサービス提供事業者が、当該個人データを取り扱わないこととなっている場合には、当該個人情報取扱事業者は個人データを提供したことにはならないため、『本人の同意』を得る必要はありません。」とされています。具体的には、「契約条項によって当該外部事業者がサーバに保存された個人データを取り扱わない旨が定められており、適切にアクセス制御を行っている場合等」が「取り扱わないことなっている場合」の典型例であるとされています(個人情報保護委員会Q&A「Q7-53」)。
したがって、OpenAIの利用規約及びアクセス制御等を検討し、「提供」に当たるかを判断することになります。
「提供」していると判断される場合には、次に問題となるのが、OpenAI社が海外法人であるため、外国にある第三者への提供の制限です(個人情報保護法28条)。
この制限をクリアするためには、以下のいずれかである必要があります。
・本人の同意を得ていること
・個人データの取扱いについて個人情報保護法第4条第1節の規定により個人情報取扱事業者が講ずべきこととされている措置に相当する措置(「相当措置」)を継続的に講ずるために必要なものとして個人情報保護委員会規則で定める基準に適合する体制を整備していること
すなわち、本人の同意を得ていれば問題ありませんが、同意取得が難しい場合には、OpenAI社が相当措置を講じているといえるかを検討することになります。
仮に、相当措置を講じているために「外国にある第三者」(同法28条1項)への提供にはあたらないことになれば、次に「第三者提供」にあたり本人の同意が必要となるのか、「委託」に伴う提供にあたり同意が不要なのかを検討することになります(同法27条5項1号)。
この点、「委託」とは、「利用目的の達成に必要な範囲内において個人データの取扱いの全部又は一部を委託すること」とされていますので(同法27条5項1号)、提供元の事業者の利用目的でのみ利用する場合が「委託」であり、提供先の事業者の利用目的で利用する場合が「第三者提供」に当たることになります。
したがって、利用規約やアクセス制御等を確認して、これらの要件を満たしているかどうかを検討していく必要があることになります。
この点、OpenAI社の利用規約(2023年4月24日時点。以下同様)では、以下のとおり記載されています。
(c) Use of Content to Improve Services. We do not use Content that you provide to or receive from our API (“API Content”) to develop or improve our Services. We may use Content from Services other than our API (“Non-API Content”) to help develop and improve our Services. You can read more here about how Non-API Content may be used to improve model performance. If you do not want your Non-API Content used to improve Services, you can opt out by filling out this form. Please note that in some cases this may limit the ability of our Services to better address your specific use case.
<筆者による訳文>
(c) サービス向上のためのコンテンツの使用。当社は、お客様が当社のAPIに提供し、又は当社のAPIから受信したコンテンツ(「APIコンテンツ」)を、当社のサービスの開発または改善のために使用することはありません。当社は、当社のAPI以外のサービスから提供されるコンテンツ(「Non-APIコンテンツ」)を、当社のサービスの開発および改善に役立てるために使用することがあります。Non-APIコンテンツがモデルのパフォーマンスを向上させるためにどのように使用されるかについては、こちらをご覧ください。お客様がご自身のNon-APIコンテンツのサービス向上のための利用を希望されない場合は、このフォームにご記入いただくことでオプトアウトできます。場合によっては、お客様の特定のユースケースによりよく対応するために、当社のサービスの能力が制限されることがあることにご注意ください。
これによれば、ChatGPTのウェブ画面の質問欄(プロンプト)に入力した個人データは、別途OpenAI社にアプトアウトの申請をして認められない限り、OpenAI社が「取り扱う」ものと考えられますので、OpenAI社に「提供」していることになるものと考えられます。
したがって、この「提供」が第三者提供にあたり同意が必要なのか、委託に伴う提供であり同意が不要なのかは、OpenAI社が自らの利用目的で利用しているといえるか等にかかってきます。この点は、「当社のサービスの開発および改善に役立てるために使用する」という利用規約の解釈によることになり、慎重な判断が必要であるもの思われます(※)。
※2021年9月に、個人情報保護委員会のQ&Aに以下が追加されました。本件では、この場面に該当するか等を検討していくことになります。
Q7-39 委託に伴って提供された個人データを、委託業務を処理するための一環として、委託先が自社の分析技術の改善のために利用することはできますか。
A7-39 個別の事例ごとに判断することになりますが、委託先は、委託元の利用目的の達成に必要な範囲内である限りにおいて、委託元から提供された個人データを、自社の分析技術の改善のために利用することができます。
以上のとおり、ChatGPTのウェブ画面の質問欄に個人データを入力することには、様々なハードルがあることが分かります(※)。
これに対し、「お客様が当社のAPIに提供し、又は当社のAPIから受信したコンテンツ」(APIコンテンツ)については、「当社のサービスの開発または改善のために使用することはありません」とされています。したがって、これを踏まえ、そもそも「提供」していないと判断できるのであれば、外国にある第三者への提供の問題(同法28条)も、第三者提供か委託かの問題(同法27条)も生じないことになります。
ただし、「提供」していないと判断できるとしても、安全管理措置の一環としての「外的環境の把握」(通則ガイドライン10-7)の義務は生じることになりますので、留意が必要です。
本稿執筆後、利用規約等が改定され、2023年4月27日時点では、利用規約からのリンク先のページに以下の記載があります(https://help.openai.com/en/articles/5722486-how-your-data-is-used-to-improve-model-performance)。
You can switch off training in ChatGPT settings (under Data Controls) to turn off training for any conversations created while training is disabled or you can submit this form. Once you opt out, new conversations will not be used to train our models.
<筆者による訳文>
ChatGPTの設定(Data Controls内)でトレーニングをオフにすることができ、それにより、トレーニングを無効にしている間に作成された会話のトレーニングをオフにすることができます。また、こちらの入力フォームから申請することもできます。一旦オプトアウトすると、新しい会話は私たちのモデルを訓練するために使用されません。
このセッティングを行えば、契約上、OpenAI社が入力データをモデルの学習のために利用することはないことになりますので、データを取り扱わないと評価することも可能になるのではないかと考えられます。
(2023年4月27日の追記は以上)
(以下、2023年6月21日追記)
この点、前述した「生成AIサービスの利用に関する注意喚起等について」において、「個人情報取扱事業者が、あらかじめ本人の同意を得ることなく生成 AI サービスに個人データを含むプロンプトを入力し、当該個人データが当該プロンプトに対する応答結果の出力以外の目的で取り扱われる場合、当該個人情報取扱事業者は個人情報保護法の規定に違反することとなる可能性がある。そのため、このようなプロンプトの入力を行う場合には、当該生成 AI サービスを提供する事業者が、当該個人データを機械学習に利用しないこと等を十分に確認すること。」との注意喚起がなされています。
ここでいう「個人情報保護法の規定に違反」というのがどの規定を指しているのか(目的外利用なのか、第三者提供違反なのか等)は明らかではありませんが、実務的には、個人情報を入力する場合には上記のセッティングが必須であることを示していると同時に、上記のセッティングをしておけば「提供」に当たらないとの解釈が可能であることを示していると理解できます。
このことは、同ページで公表されている「OpenAI に対する注意喚起の概要」において、OpenAI社に対し、「収集した情報に要配慮個人情報が含まれていることが発覚した場合には、できる限り即時に、かつ、学習用データセットに加工する前に、当該要配慮個人情報を削除する又は特定の個人を識別できないようにするための措置を講ずること」との注意喚起がなされていることからも裏付けられます。
なぜなら、少なくとも学習用データセットに加工する作業により、個人情報(要配慮個人情報)を取得していることになると評価するとの考えが示されているからです。
個人情報を入力するのであれば、ChatGPTにおいて学習用データとして利用しないように設定する、あるいはAPI経由で利用するなどの対応が実務上必須となると考えられます。(2023年6月21日の追記は以上)
また、入力する情報が秘密保持契約(NDA・CA)の秘密保持条項の対象となっている場合に、ChatGPTの質問としてそれを入力することが、契約上の義務違反とならないかが問題となります(※)。
例えば、以下のような条項が秘密保持条項の典型例です(経済産業省「秘密情報の保護ハンドブック ~企業価値向上にむけて~【参考資料2】各種契約書等の参考例 (令和4年5月改訂版)」 )。
第○条(秘密情報等の取扱い)
1.甲又は乙は、相手方から開示を受けた秘密情報及び秘密情報を含む記録媒体若しくは物件(複写物及び複製物を含む。以下「秘密情報等」という。)の取扱いについて、次の各号に定める事項を遵守するものとする。
① 情報取扱管理者を定め、相手方から開示された秘密情報等を、善良なる管理者としての注意義務をもって厳重に保管、管理する。
② 秘密情報等は、本取引の目的以外には使用しないものとする。
③ 秘密情報等を複製する場合には、本取引の目的の範囲内に限って行うものとし、その複製物は、原本と同等の保管、管理をする。また、複製物を作成した場合には、複製の時期、複製された記録媒体又は物件の名称を別紙のとおり記録し、相手方の求めに応じて、当該記録を開示する。
④ 漏えい、紛失、盗難、盗用等の事態が発生し、又はそのおそれがあることを知った場合は、直ちにその旨を相手方に書面をもって通知する。
⑤ 秘密情報の管理について、取扱責任者を定め、書面をもって取扱責任者の氏名及び連絡先を相手方に通知する。
2.甲又は乙は、次項に定める場合を除き、秘密情報等を第三者に開示する場合には、書面により相手方の事前承諾を得なければならない。この場合、甲又は乙は、当該第三者との間で本契約書と同等の義務を負わせ、これを遵守させる義務を負うものとする。
3.甲又は乙は、法令に基づき秘密情報等の開示が義務づけられた場合には、事前に相手方に通知し、開示につき可能な限り相手方の指示に従うものとする。
前述のとおり、利用規約において「当社のサービスの開発または改善のために使用する」(Non-APIコンテンツ)又は「当社のサービスの開発または改善のために使用することはありません」(APIコンテンツ)とうたわれているサービスに、秘密保持の対象になっている情報を入力することが、秘密保持義務を定めた上記のような条項に違反しないかをそれぞれ検討することになります。
※なお、法的には、不正競争防止法の不正競争(特に同法2条1項7号)に当たる可能性についても留意が必要です。
(定義)
第2条 この法律において「不正競争」とは、次に掲げるものをいう。
七 営業秘密を保有する事業者(以下「営業秘密保有者」という。)からその営業秘密を示された場合において、不正の利益を得る目的で、又はその営業秘密保有者に損害を加える目的で、その営業秘密を使用し、又は開示する行為
経済産業省「逐条解説 不正競争防止法」によれば、ここでいう「『不正の利益を得る目的』(図利目的)とは、競争関係にある事業を行う目的のみならず、広く公序良俗又は信義則に反する形で不当な利益を図る目的のことをいう。」とされていますので、これに当たるかが問題となります。
ChatGPTの質問欄やAPIでデータを入力する際、データが著作物である場合に、著作権を侵害しないかを検討する必要があります。
これは、どのような態様・目的で利用するか(プロンプトでどのような作業をさせる指示をするか)によって結論が変わってくると考えられます。
例えば、著作物である小説を丸ごと入力して要約を作らせれば、翻案権や同一性保持権の侵害になる可能性があります。あるいは、他者が著作権を有するプログラムのソースコードを入力して改変するようなケースも同様です。
他方、その入力が「思想又は感情を自ら享受し又は他人に享受させることを目的としない場合」(著作権法30条の4)等の要件を満たせば、著作権を侵害することにはなりません。この点は、後記「3」で詳述します。
ChatGPTは、OpenAI社が提供するサービスの1つに過ぎず、ほかにもAPIを利用して様々なサービスを利用することができます。
例えば、promptとcompletionの組み合わせを与えて再学習(Fine-tuning)を行ったり、文章のベクトル化(embedding)などを行うことができます。このようなサービスは、入力した情報を統計処理して結果を出力するものです。これを利用する場面についても、社内でルール付けしておくことが考えられます。
ここで検討する利用場面とは、AI契約ガイドラインでいうと「学習段階」での利用ということになります(下図②及び③)。
個人情報保護法が保護しているのは「個人に関する情報」(個人情報保護法2条1項、2条7項)であるため、特定の個人との対応関係が排斥されている情報は、個人情報の規制の対象外です(Q2-5、通則ガイドライン2-8も参照)。したがって、出力されるモデルやパラメータには、個人情報保護法の適用はありません(上図の「学習済みモデル」は個人情報保護法の適用がないということです)。
また、そのような統計情報に加工する処理(上図①~③)についても、「統計データへの加工を行うこと自体を利用目的とする必要はありません」とされています(Q2-5)。
つまり、統計的な処理を行うために個人情報を入力すること(上図①~③)は個人情報の「利用」に当たらず、出力された統計的な情報(上図「学習済みモデル」)も個人情報保護法の適用がありませんので、追加学習等に個人情報を利用することに個人情報保護法上大きな問題はないと考えられます。
なお、ベクトルデータそのものは統計情報に過ぎないといえますが、そのベクトルデータを利用して近傍検索を行うようなケースでは元の文章と紐付けして保存する形になりますので、そのデータ全体が個人情報(あるいは仮名加工情報)に当たることになります。この点の詳細は、特集記事「ChatGPTと仮名加工情報・個人情報」をご参照ください。
この点については、前述したとおり、利用規約においてAPIコンテンツについては「当社のサービスの開発または改善のために使用することはありません」とされていますので、それを踏まえて、秘密保持義務に違反しないかを考えていくこととなります。
2019年1月1日施行の改正著作権法により、以下の権利制限規定が整備されています。
・権利者の利益を通常害さない行為類型(30条の4、47条の4)
・権利者に及ぶ不利益が軽微な行為類型(47条の5)
まず、著作権法30条の4は以下のとおり定めています。
(著作物に表現された思想又は感情の享受を目的としない利用)
第30条の4 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合
したがって、著作物を機械学習の学習用データとして利用すること等(上図①~③)は、「著作物に表現された思想又は感情」を享受する目的としておらず、情報解析の用に供する場合であるため、著作者の許諾は原則として不要と考えられます。
「ただし,当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合」には許諾が必要ですので留意が必要です(権利を主張する側(著作権者側)に立証責任あり)。
なお、ここで「いずれの方法によるかを問わず」とされていますので、自社内で著作物を複製・翻案する場面(上図①)のみならず、他社に提供すること(上図②及び③)なども可能であるとされており、その点も問題ありません。
また、著作権法47条の5は以下のとおり定めています。
(電子計算機による情報処理及びその結果の提供に付随する軽微利用等)
第47条の5 電子計算機を用いた情報処理により新たな知見又は情報を創出することによつて著作物の利用の促進に資する次の各号に掲げる行為を行う者(当該行為の一部を行う者を含み、当該行為を政令で定める基準に従つて行う者に限る。)は、公衆への提供又は提示(送信可能化を含む。以下この条において同じ。)が行われた著作物(以下この条及び次条第二項第二号において「公衆提供提示著作物」という。)(公表された著作物又は送信可能化された著作物に限る。)について、当該各号に掲げる行為の目的上必要と認められる限度において、当該行為に付随して、いずれの方法によるかを問わず、利用(当該公衆提供提示著作物のうちその利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度その他の要素に照らし軽微なものに限る。以下この条において「軽微利用」という。)を行うことができる。ただし、当該公衆提供提示著作物に係る公衆への提供又は提示が著作権を侵害するものであること(国外で行われた公衆への提供又は提示にあつては、国内で行われたとしたならば著作権の侵害となるべきものであること)を知りながら当該軽微利用を行う場合その他当該公衆提供提示著作物の種類及び用途並びに当該軽微利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 電子計算機を用いて、検索により求める情報(以下この号において「検索情報」という。)が記録された著作物の題号又は著作者名、送信可能化された検索情報に係る送信元識別符号(自動公衆送信の送信元を識別するための文字、番号、記号その他の符号をいう。)その他の検索情報の特定又は所在に関する情報を検索し、及びその結果を提供すること。
二 電子計算機による情報解析を行い、及びその結果を提供すること。
三 前2号に掲げるもののほか、電子計算機による情報処理により、新たな知見又は情報を創出し、及びその結果を提供する行為であつて、国民生活の利便性の向上に寄与するものとして政令で定めるもの
2 前項各号に掲げる行為の準備を行う者(当該行為の準備のための情報の収集、整理及び提供を政令で定める基準に従つて行う者に限る。)は、公衆提供提示著作物について、同項の規定による軽微利用の準備のために必要と認められる限度において、複製若しくは公衆送信(自動公衆送信の場合にあつては、送信可能化を含む。以下この項及び次条第二項第二号において同じ。)を行い、又はその複製物による頒布を行うことができる。ただし、当該公衆提供提示著作物の種類及び用途並びに当該複製又は頒布の部数及び当該複製、公衆送信又は頒布の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
これは、著作権法30条の4に該当しない利用が必要となった場合にも、法改正ではなく政令により利用が可能になる可能性を残す規定となっていますので、これにより利用することが可能になるケースも考えられます。
ただし、いずれにせよ、契約上の制限には注意が必要です。
例えば、インターネット上に画像や文章などをアップロードさせているサイト等の中には、サイトの利用規約で機械学習の学習用データとして利用することや、コンピュータによる自動的な情報収集(クロール)を明示的に禁止しているものがありますので、注意が必要です(これは、著作権法30条の4が契約によりオーバーライトできるかという論点でもあります。)。
出力された回答が個人情報である場合には、個人情報保護法の規制を受けることになります。
特に、不適正利用の禁止(19条)及びデータの内容の正確性の確保等(22条)に注意が必要であると考えられます。
すなわち、個人情報保護法19条は「違法又は不当な行為を助長し、又は誘発するおそれがある方法により個人情報を利用してはならない」として不適正な利用を禁止しています。
これに当たる具体例として、通則ガイドラインは「採用選考を通じて個人情報を取得した事業者が、性別、国籍等の特定の属性のみにより、正当な理由なく本人に対する違法な差別的取扱いを行うために、個人情報を利用する場合」をあげています(通則ガイドライン3-2の「事例5」)。
AIが出力した回答が差別的なものであるようなケースでは、その回答をそのまま利用することが、個人情報の不適正利用に当たることがあり得るということになります。
また、大規模言語モデル(LLM)をはじめとするAIの回答が「正確」なものかについては疑義があります。したがって、不正確なデータをそのまま利用することは、個人情報保護法22条が定める「利用目的の達成に必要な範囲内において、個人データを正確かつ最新の内容に保つ」義務に違反する恐れもあります。
出力された回答は、内容面で差別等の問題がないか、正確性に問題がないかを確認してから利用することが必要であると考えられます(これは、個人情報・個人データである場合の個人情報保護法の観点からのみならず、一般不法行為や「炎上」リスクの観点からも重要であると考えられます。)。
AIが出力したデータが著作権を侵害しないかも、検討する必要があります。
ただし、大規模言語モデル(LLM)は、その性質上、特定の文章への依拠性が認められる可能性は低いのではないかと考えられます(ただし、この点は専門家によって見解が分かれています。)。
すなわち、著作物の「複製」とは「有形的に再製すること」であるとされており(著作権法2条1項15号)、他人の著作物に依拠して同一あるいは類似のものを再製することがこれに当たるとされています。
より具体的には、原著作物との「同一性(類似性)」と原著作物へ「依拠性」が要件であるとされています。「同一性(類似性)」があるといえるかは、原著作物の「内容及び形式を覚知させる」か(最判昭53.9.7(ワン・レイニー・ナイト・イン・トーキョー事件))あるいは「本質的な特徴を直接感得することができる」か(最判平13.6.28(江差追分事件))といった基準で判断されます。「依拠性」については、多くの裁判例において、類似しているという間接事実から推認されており、「多くの著作物の場合は、相当程度類似しているか否か、つまり依拠していない限りこれほど類似することは経験則上ありえない、ということで立証されることになろう」とされています(中山信弘「著作権法 第2版」有斐閣、2014年)。
しかしながら、LLMで生成された文章は、原著作物にアクセスすることが全くできていなくても類似することがあり得るため、類似しているという事実から依拠性を認定することは難しいのではないかと考えられます。むしろLLMの仕組み及びLLMで生成された文書であることが立証できれば、依拠性について反証に成功するようにも思われます。
もっとも、例えば、特定のアニメのキャラクターだけを学習させてそれに類似する絵を描かせるようなことをすれば、依拠性が認められることはあるように思われます。
今後の裁判例の蓄積が待たれるところです。
文化庁及び内閣府が2023年5月30日に「AIと著作権の関係等について」を公表しました。これによれば、上述のとおり、従来どおり類似性及び依拠性から判断されることになり、事実関係次第では著作権を侵害することもあり得るとの見解が示されています。今後の裁判例や議論の蓄積が待たれるところです。
■AIを利用して生成した画像等をアップロードして公表したり、複製物を販売したりする場合の著作権侵害の判断は、著作権法で利用が認められている場合※を除き、通常の著作権侵害と同様
※ 個人的に画像を生成して鑑賞する行為(私的使用のための複製)等
■生成された画像等に既存の画像等(著作物)との類似性(創作的表現が同一又は類似であること)や依拠性(既存の著作物をもとに創作したこと)が認められれば、著作権者は著作権侵害として損害賠償請求・差止請求が可能であるほか、刑事罰の対象ともなる
(2023年6月21日の追記は以上)
以上のとおり、ChatGPTをはじめとするAIの利用については、様々な法的な論点が存在します。
しかしながら、日本の法制度は、個人情報保護法においても著作権法においても、統計的な処理・出力については積極的に利活用する方向で法制度や解釈が整っているように思われます。
以上を前提に、本稿で述べた論点のうち重要なものを一覧表にしたのが以下の表です。
利用企業としては、各サービスの利用規約等を検討し、ベンダ側がデータをどのように利用しているのかを把握したうえで、上記の場面ごとに場合分けして利用の是非をルール化していけば、問題なく利用することができるように思われます。
なお、本稿は、特定のサービスについて法的助言を与えるものではありませんので、実際の利用に際しては、弁護士等へご相談いただければと存じます。